 ]]>
]]>
I had just upgraded NuGet packages - a seemingly innocent thing to do. Everything compiles fine and I tried to run my ASP.NET WebAPI service. Testing in Postman works fine, but when I try to let the browser call an endpoint (any endpoint), I get a mysterious 500 server error with a rather unhelpful payload message of {"message":"An error has occurred."}. However, even with Chrome accessing the service, a breakpoint in the endpoint showed me that the code was executing fine. The problem is clearly occurring inside the ASP.NET engine when trying to send the response back to the browser.
Chrome sends several headers that Postman does not, so I tried copying those headers into Postman to see if any of them made the difference. About half of them required use of the Postman interceptor, and I decided to do some googling before fiddling with that. Couldn't turn anything up. I couldn't even find a way to trace down the error, although I had a nagging feeling that the compression header might be related, since it was one of the key headers that Postman wouldn't send (Accept-Encoding:gzip, deflate, sdch).
And that's when I suddenly remember to look at the Windows Event Viewer. And sure enough, in the Application log I find a pair of error messages:
My hunch was right: something wrong with the compression. Why did this suddenly occur? I have no idea. I hadn't deleted files out of Temp recently. My NuGet package upgrades were for ancillary libraries, but not for ASP.NET itself. But the solution was trivial: as suggested by Event ID 2264 -- IIS W3SVC Configuration, I just had to create the directory manually, and then everything was working again.
]]>
]]>
]]>The first beta release of FlightNode is now alive and in the hands of testers. So what's been delivered?

]]>"Wow, you'd think nothing had been happening for the past two months. But that's not the case at all. There are now 6 different GitHub repositories (perhaps a few too many). November and December were heads-down coding months. But now the product is almost ready for an MVP launch... and that has me thinking about error handling. Specifically, logging."
]]>"Here is a a brief demonstration of authentication and authorization using the FlightNode.Identity API. Significant help developing this received from ASP.NET Identity 2.1 with ASP.NET Web API 2.2 (Accounts Management) by Taiseer Joudeh."
This project builds off the IbaMonitoring.org project I took on in 2010. I've been approached by a conservation organization here in Texas, asking for my help to build something similar to that site, but tailored for their purpose (I need to get their permission before using their name). What they want and need is more than I can provide in my "spare time." And I know of other programs that would be interested in using components of these projects.
]]> Building an open source platform to support conservation efforts has been a dream of mine for several years - but I need help! I will build out the requirements and more information about the project and architecture (fyi, using ASP.NET WebAPI and Angular.js), and I expect to write much of the code. Do you think you might be interested in contributing? Even if it is only to develop one feature, your help would be fantastic. And it would be a great opportunity to get more experience in API development and/or Angular.js.Code will be posted at https://github.com/FlightNode. Let me know if you're interested, and I'll invite you to join the FlightNode organization on GitHub.
]]>Here are a few tips for moving toward mastery of this crucial part of the .NET development ecosystem.
]]> It's Just a Zip FileLike many of its older cousins in the world of package management, .nupkg, the file extension for NuGet packages, is just an alias for .zip. Change the filename from abc.nupkg to abc.zip and it will open beautifully from your favorite zip client. From time to time, it can be quite useful to open up a NuGet package and see what is inside.
Of course NuGet uses a particular file layout within the package, and you wouldn't want to create the .nupkg by hand. Instead, you describe the desired package with a .nuspec file (which you should keep in source control), and then use the nuget pack command to create your package (which you should not keep in source control. Use an artifact repository instead).
Incidentally, you can also nuget pack your csproj file, but you have less control over the outcome this way.
As with most tools, you'll get more out of it if you start reading the documentation. I have particularly enjoyed the command line reference for working with nuget.exe. Note: this is basically, but not exactly, the same as the Package Manager PowerShell Console. Use the former for automation, or manual execution of NuGet commands. Use the latter in Visual Studio for advanced functionality.
With both nuget.exe and the PowerShell console – but not in the Package Manager gui – you can install older or pre-release versions of packages by providing the version number:
PM> Install-Package <SomePackageId> -version <number>
Or
C:\YourProject> nuget.exe install <SomePackageId> -version <number>
There are two primary use cases for this:
Some teams publish pre-release versions of their packages. While you wouldn't typically want these in production, it can be useful to try out the pre-release in anticipation of up-coming enhancements or API changes.
I'm guessing that the majority of business .NET applications were written before NuGet came around. Many of those have dependencies on old packages, which were installed manually. A mad rush to replace manual references with NuGet packages might not be wise; you need to take time and evaluate the impact of each package. It can be useful to start by installing the same version as you already utilize, but from a NuGet package. Then, you can carefully work on upgrading to newer versions of the package in a deliberate test-driven manner.
Most .NET devs probably don't realize that the .nupkg files can be used for much more than installing packages inside of .NET projects in Visual Studio and SharpDevelop. A basic .nupkg file differs from a self-installing .exe or an .msi file in that it is just a zip file, with no automation to the install. This can be useful for distributing static files, websites, and tools that don't need Windows registry settings, shortcuts, or global registration. Lets say that you pack up a website (.NET equivalent of a Java WAR file), and you want to install it in c:\inetpub\wwwroot\MySite. At the command prompt:
C:\LocationOfNuPkg> nuget.exe install <YourPackageId> -Source %CD%
-o c:\inetpub\wwwroot\MySite
If you are running IIS with the default configuration, then you've just installed your website from a .nupkg artifact. Because NuGet is retrieving the package from an artifact repository, you only need a tool to push this command to that server, and then the server will put the "current version" from the repository.
But you can also do more, and this is where Chocolatey comes in. Using the same .nupkg name, Chocolatey does for Windows what NuGet did for .NET applications: supports easy discovery, installation, and upgrade of -packages- applications. Once you have Chocolatey itself installed (follow directions on the home page), you install many common open source tools from the command line. For example, this article has neglected to mention that you need to download nuget.exe in order to run NuGet from the command line. For that, you can simply run:
C:\>choco install nuget.commandline
This will install nuget.exe into c:\ProgramData\Chocolatey\bin, which automatically puts it into your command path. As with NuGet, versioning can be a huge benefit compared to distributing a zip or msi file.
The key difference between Chocolatey and NuGet is that the choco command runs a PowerShell install script inside the package. Basically anything you would have done in the past with an msi, perhaps built-up with a WiX xml file, you can do in a PowerShell script. Arguably, you have more control over your install, and it will be easier to support scripted installation processes. Again, the real power here is in automation. It won't give you a nice gui for walking your users through the install (although you could embed a call to an msi inside your .nupkg file), but it does facilitate smoother rollout of applications to servers and multiple desktops.
Most companies are not going to be comfortable with the idea of their developers throwing the company's proprietary NuGet packages out on the Internet for the whole world to find. Instead, they'll want to install a piece of server software that acts as a local repository. The Hosting Your Own NuGet Feed lists the primary options available. So far, I've been relatively happy with NexusOSS, which also allows me to host Maven packages form my Java teammates, and npm packages for my Node.js team (as well as a few others).
As this article is already quite long, look for a future post with more information on using NexusOSS as a private repository for NuGet and Chocolatey packages.
]]>A friend asked me what I thought of Code. When I installed it a few weeks ago, my first reaction was: this is nice, if you're not used to Atom already. Never satisfied with a simple gut reaction, I thought for a moment, and realized that I had not looked closely at Microsoft's additions – particularly, debugging.
]]> Overall ImpressionsBoth are beautiful text editors. There is something about the presentation that makes me simply enjoy working with text files more than when I open them in Notepad++. Aesthetics are worth something. That said, Notepad++ is still a great tool and I will not be rid of it any time soon (especially for large files).
I've been using Atom daily for the past three months, and have spent just a few full days in Code. Exploring the two side-by-side, there are both clear similarities and differences. Right out of the box Code does win in one respect: it provides me with a list of recently opened files. I'm sure there's a plugin for Atom, but this should be standard.
Code changes the keybindings, but I can't let that dissuade me. Code does not have jshint built-in, a tool that has been of great help to me as I move from C# to pure JavaScript. But it does detect errors, such as undeclared variables. Code, so far, eschews the plugin architecture of Atom. For a preview release of a lightweight IDE, that probably makes sense. Atom is an interchangeable swiss army knife, and Microsoft is aiming for a dedicated code editor. That said, the rest of this review will look at four great features that are accessible from a vertical toolbar in Code, comparing them to equivalents in Atom.
In Atom, I have autocomplete-plus and it does a reasonable job of helping me finish my thoughts. But it is not a substitute for powerful IntelliSense. While there are language-specific autocomplete packages for many dialects, oddly enough I cannot find anything for JavaScript. Code, on the other hand, has some impressive auto completion, which applies equally for built-in JavaScript functionality and command-completion for local variables.
Code
Atom
This presents open files in a list, and the application does not use the familiar horizontal tabs metaphor - instead, you see a vertical list of "Working Files". This is useful when more than a handful of files are open, but it certainly takes some getting used to, and I have not decided if I like it yet.
The list of files is perfectly useful. Code does not have the Git-status color coding of Atom, but more on Git below.
Here's an interesting feature: right-click on a file, choose Select for Compare, then right-click another file and choose Compare. You get a reasonable diff comparison. Nice, but not very functional in this setting. More important elsewhere.
Of course, Atom also has packages such atom-cli-diff (Git-like) and compare-files (GitHub-like). My first impression is that the Code diff is better, but that might be based on what I'm used to already.
Overall, I find the two different but equally useful.
Code
Atom
When you've opened a folder, this will search every file in the folder. And it is fast. But so is Atom's Find in Project. Code just makes it more visible through the menu bar. Both have regular expression support, and my early impression is that they are pretty well matched. That said, I do like Atom's display of the line number next to the match.
Code
Atom
In Atom, I have installed the Git-Control plugin. For the most part, I prefer using Bash, but occasionally it is convenient to use the development environment. Visual Studio's support is pretty good for all of the basic functions, and so is Git-Control. But I don't like the way that both of them go from unstaged to committed, seemingly bypassing staging. Although it sometimes feels like staging is an extra, unwanted step, Git has it for a reason. And it can turn out to be handy from time to time. So don't hide it from me. Code gets this right.
Remember that file compare? Now we see it shine: Code gives you quick access to viewing changes on your unstaged and staged files.
Overall, the Code interface to Git is better, except for one flaw (for now): Commit messages are one-line only. And if you push that Enter key trying to add a line break, then you've just finished your commit. Commit messages often need to be multi-lined, so I hope that Microsoft changes this.
Code
Atom
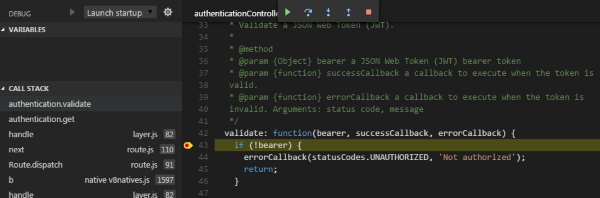
There are some quirks, but this is promising. As you can see in this screenshot, variables aren't displaying for me, so I don't know what values I'm dealing with. No doubt that will improve with time. But at least it is possible to walk through the stack trace and try to understand what's going on. This is going to be powerful and is reason enough to keep this Visual Studio Code around.
That said, there is a node debugger project for Atom. The pictures look promising, but even the maintainer admits it is buggy. I cannot get it to work at all - opening the debugger palette, you are presented with an opportunity to fill in a few paths. But the fields, at least in my install, are not enabled.
Atom is much more versatile, but Visual Studio Code is already a strong competitor. And is more stable; I've not yet experienced any bugs or program failures. I began writing this over a week ago, and decided to force myself into daily Code use before publishing. At this point, I miss a few things, but I am starting to get hooked on Code.
For more details on the features in Code, see John Papa. I purposefully avoid reading this - except the debugging overview - and other posts in order to draw my own conclusions. But this series of posts is too good not to promote.
]]>
Adding two wheels: increases the complexity and number of moving parts. Must be worthless.
The research was carried out in an exercise where students applied a small set of standard refactoring techniques to an application used at their university.
I look at code metrics from time-to-time, and have written company standards on which metrics to look at and what thresholds to be concerned about. That is, I'm not opposed to metrics. Nevertheless, the use of code metrics is problematic in this paper. Let's look at each metric, which was calculated with Visual Studio's built-in tools:
Maintainability Index increased slightly. Win!
Cyclomatic Complexity increased slightly. Lose! The problem is, the total complexity is not all that meaningful. What is meaningful is the complexity of each class. Many times refactoring involves creating some new classes. These new classes by definition introduce a small complexity factor - and they could well be the reason for the increase. In looking at this number, it would have been better to look at the complexity of individual classes. Did that increase? Did the average complexity per class increase? We simply do not know.
Depth of Inheritance no change. Draw!
Class Coupling increased. Lose! On the other hand, more classes probably means that the code is better structured. I can only speak subjectively, but on its face, I cannot see anything negative about 7% increase in class coupling.
Lines of code increased. Lose! Measuring lines of code can be helpful in identifying methods and classes that are "too big" and need to be split up. But otherwise it is not helpful. Refactoring often means creating new classes and methods. Visual studio does not count the brackets {} for these - but each new class and method has a signature, and that signature does count.
Duplication was not measured, because Visual Studio does not calculate code duplication. This might have been a truly useful metric, particularly since one of the primary goals in refactoring is to remove code duplication.
Code Analysis Warnings was not measured, perhaps because they were simply overlooked. Refactoring should aim to eliminate common errors and warnings reported by static code analysis tools, such as FxCop, which is built into Visual Studio.
Reading the paper, you will find this important phrase in the statistical analysis for both performance and "changeability" (maintainability): "do not reject the null hypothesis." The null hypothesis is that the refactoring will not have any significant impact. In other words, the statistics do not support the positive hypothesis that performance will improve and the application will be more maintainable.
Performance. It is generally a given that you refactor for maintenance, not for performance. It is well known that performance problems sometimes require brute force solutions that are not as maintainable. In other words, this is an acknowledged tradeoff anyway.
Changeability. There is some legitimate criticism that less experienced programmers will have a harder time reading nicely object-oriented code. Thus less experience programmers, such as university students, may rate the changed code as less easy to maintain. Since programming teams typically have a mix of experience, this is very relevant. Each group should assess on their own which refactoring techniques actually tend to improve their codebase.
The benefits tend to be subtle. Some of the most-used techniques focus on clear naming conventions and on removing duplication. The benefit to these two are most apparent when fixing bugs - something that was not explored in the paper.
It is not my intention to bash the authors. The choice of topics is probably a good one, but the skimming through the paper, the authors' lack of experience in real world programming is apparent. Authors who promote refactoring, such as Martin Fowler and "Uncle" Bob Martin, have spent decades in the consulting field. As such, they've worked with a wide diversity of companies, codebases, and programmers. At the risk of sounding anti-white tower: I trust their real world experience over university lab experience.
***
Ultimately, each group should decide on their own how and when to incorporate code refactoring into their daily habits. For many teams, it is simple as the old Boy Scout rule: leave the code cleaner than you found it. Take "silver bullet" promises with a grain of salt, but don't allow a well-intentioned but poorly-constructed study to dissuade you from good engineering practices.
The paper: http://arxiv.org/ftp/arxiv/papers/1502/1502.03526.pdf
]]>
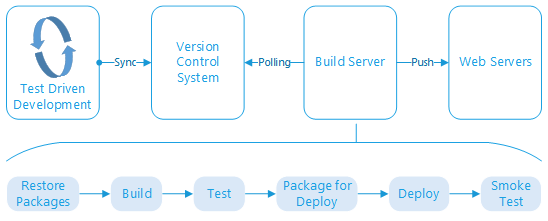
I considered using Node.JS, but the project's desired timeline pushes me back to the familiar territory of C#. The backend database is flexible. A NoSQL solution could be appropriate, but I believe the data will be most portable (and thus useful to the client) stored in a SQL solution, which could be Microsoft SQL Server or MySQL. If push notifications are required, then I will likely stick with Microsoft's SignalR hosted on the API server.
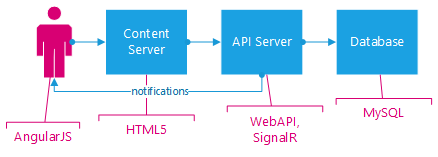
Configuring the build server to run all of the steps shown above has been an exciting adventure, and I'm not fully there yet. Setting up Visual Studio locally, and connecting to GitHub for version control, was trivial. From there, getting to the push-button deployment took me about two days of effort, with a good deal of experimentation and blog reading. I did not try to carefully document every step along the way, so for the most part I will only be sketching out the steps and final state, rather than providing details.
The most important pieces I am missing are: automatic rollback if the smoke test fails, and the ability to deploy to anything other than my integration testing environment. Naturally I have duplicate systems for acceptance testing and for production*, with each system on a different subdomain of my primary hosting account. (* with the exception that I don't know the ultimate destination of the content server).
Thanks to my MSDN license, I have a renewing $150 / month credit on Microsoft Azure. It is a fantastic promotion. I configured a modest A2 virtual machine (VM) (Microsoft Windows Server 2012, 2 cores, 3.5 GB memory, 126 GB local disk). Thus far it has cost me about $1 of credit per day.
Once the server was up-and-running, I had to install the tools of the trade. This is a bare-bones server, after all.
| Program | Purpose | Installation Method |
|---|---|---|
| TeamCity | Continuous Integration/Delivery (task runner) | msi download from JetBrains |
| Chocolatey | Windows application package manager, for installing Windows apps (makes installs very convenient and command-line driven. | Run the powershell script at chocolatey.org. |
| Visual Studio 2013 Community Edition | Provides msbuild.exe and mstest.exe, critical for .NET compilation and testing. | Microsoft Web Platform Installer |
| Web Deploy 3.5 | For pushing web site files out to remote servers through a command line interface. | Microsoft Web Platform Installer |
| NuGet | I had already installed NuGet for third party .NET package downloads before realizing that I needed Visual Studio 2013 for mstest.exe, so this was probably unneccesary as a stand-alone install. | c:\>choco install nuget.commandline |
| NotePad++ | Because at some point you'll want a text editor that is better than notepad, and this one is my long-time favorite freeware replacement. | c:\>choco install notepadplusplus |
| Node.js | In this case, my real aim is to get the Node Package Manager (NPM), which will be useful for the web site content, as you'll see below. | c:\>choco install nodejs |
| Grunt | JavaScript task runner, for automating tasks such as concatenating and minifying JavaScript (JS) and Cascading Style Sheet (CSS) files. |
*>npm install grunt *>npm install grunt-cli |
| Bower | Yet another package manager, this time for JavaScript packages. Similar to NuGet or NPM, but targeted specifically to retrieving client-side JavaScript libraries. |
*>npm install bower *>npm install grunt-bower-install |
* for Grunt and Bower, the install needs to be both global and in the website's working directory. Thus issue the command once with the -g flag for global. Find TeamCity's working directory for the website project, and open the command prompt there. Run the commands as shown above, without -g, to install locally. All other bower packages that I used on my development computer are downloaded as needed by grunt-bower-install. I also had to manually run the following once in the working directory, before getting Grunt working in TeamCity:
*>npm install
*>grunt
Time is in short supply, so this has been hastily written. More project configuration details to follow in a second post.
]]>Two incidents this week have driven home the value of being able to study the source code of frameworks I code with. One the one hand, I was using NServiceKit.OrmLite for database access, and needed to understand how it constructs its SQL. Through study of the code, I was able to find and remediate a limitation in the wildcard handling*.
]]> And while working on that data access code, a coworker challenged my understanding of theList<T> data structure. I thought that it did not guarantee that elements would remain ordered in the manner in which they were entered. With that in mind, I have been (ab)using the Queue<T> whenever I've been concerned about retaining the original input order (for example, to store query results when the query itself is ordered).
What drove me to that incorrect conclusion? Some years ago, I saw mysterious behavior on data stored in a List. The data did not come out in the order I expected, causing a visible bug. Reading in the MSDN documentation, I found that:
The List<T> is not guaranteed to be sorted. You must sort the List<T> before performing operations (such as BinarySearch) that require the List<T> to be sorted.
With the evidence in front of my eyes, I understood this to mean that the input order was not guaranteed to stay that way. How could this be? I assumed there was something about the way that List storage is expanded, which could re-arrange the pointers arbitrarily – contributing to the high performance of this data type.
Suddenly recalling that Microsoft has opened up parts of the .Net code as "reference material", and feeling discomfited by this long-held assertion, I sought out answers today. And what did I find? That the List and the Queue are both backed by arrays. And arrays do not spontaneously re-arrange themselves.
So now I go back and ask why Microsoft decided to make this statement about sorting. Clearly, they just mean that it is not, for instance, alpa-numerically sorted. Well, who would have expected that anyway? My folly was in assuming that this statement could not be as basic as it really is. Surely, I rationalized years ago, it was referring to something fundamental about the type, not about programmers being dumb. So I outsmarted myself. And thanks to the source code, now I know better: use the List all the time. Unless you need a Queue so that you are removing items from a collection as you access them (through dequeuing/popping).
* I should submit a pull request to the maintainers. The powerful ExpressionVisitor has an utterly unnecessary upper in its wildcard handling:
case "StartsWith":
statement = string.Format("upper({0}) like {1} ", quotedColName, OrmLiteConfig.DialectProvider.GetQuotedParam(args[0].ToString().ToUpper() + "%"));
break;
case "EndsWith":
statement = string.Format("upper({0}) like {1}", quotedColName, OrmLiteConfig.DialectProvider.GetQuotedParam("%" + args[0].ToString().ToUpper()));
break;
case "Contains":
statement = string.Format("upper({0}) like {1}", quotedColName, OrmLiteConfig.DialectProvider.GetQuotedParam("%" + args[0].ToString().ToUpper() + "%"));
break;
Those upper function calls will cause the SQL Server query optimizer to do a table scan instead of an index scan. It should only be used if your database is configured with a case-sensitive collation – whereas the default setting is case insensitive. The use of upper should be configured through a property on this class.
I look forward to re-reading it in the near future. For now, I will satisfy myself by re-collecting and re-pondering a few of those notes, starting with the topics of Knowledge and Diversity (from Ch 4 - The Information-Innovation System)
]]> Knowledge“… people's expertise is not the most important indicator of their performance. Instead, what actually makes a difference is their connectivity in the organization.”
As I think back on my career, I can see the truth of that. As an individual programmer, it can be tempting to keep your head down and "merely" stay focused on your work. But it you want to improve the environment, and if you want foster a high performing team, then you'll have to go beyond the narrow confines of self. You need to get to know other teams, learning about what drives their good days and bad.
These other teams hold the business requirements that feed into the software development, they review the provisional output, they install the output, they support it after the fact. Without strong connections to the rest of the organization, a software development shop is likely to end up producing product that does not satisfy end users and does not meet the company's objectives.
Of course Appelo goes into more detail than this snippet provides.
Diversity and inclusiveness are two essential pre-requisites for success in all human endeavors. Not everyone shares that idea, and for those of us who hold these ideas as key values, it is often still a struggle to express them positively and holistically.
In his characteristic way, Appelo uses scientific metaphors to help us understand the importance and meaning of diversity. He then links that directly to key aspects of management and software leadership - particularly warning us of "the tendency to hire lookalikes." Describing what I have always called unity in diversity, Appelo concludes this section by acknowledging that "There has to be some balance and sufficient common ground so that all diverging views are still connected in a bigger pattern."
It is well known that the IT industry has a dearth of diversity, cutting across many different demographics. Hopefully, this section helps a few more people understand the creative strength that can come from having teams composed of people with different experiences and perspectives, who are nevertheless able to strive together in pursuit of the organization's goals.
]]>